
I am a third-year Ph.D. candidate (expected: 2028) of Computer Science at Peking University (PKU), advised by Prof. Li Yuan (PKU, 袁粒).
My research interest includes multi-modal understanding, multi-modal generation and large unified model.

Google Scholar: 🔭 Google Scholar (full public papers).
GitHub: 🐙 GitHub (full open-source codes).
Hugging Face: 🤗 Hugging Face (full open-source models & datasets).
PKU Email: 📫 linbin.ece@stu.pku.edu.cn
Google Email: 📫 linbin203279@gmail.com
🔥 News
- 2025.07: 🎉🎉 One paper have been accepted by IEEE Transactions on Multimedia (TMM)! MoE-LLaVA!
- 2025.06: 📣📣 The Open-Sora Plan has released version 1.5 and reached 12,000 stars on GitHub. At the same time, we are launching UniWorld-V1!
- 2025.03: 📣📣 Thrilled that Video-LLaVA ranks in Top 1 of the Most Influential EMNLP 2025 Papers!
- 2025.02: 🎉🎉 One paper have been accepted by CVPR 2025! WF-VAE!
- 2025.01: 📣📣 Honored as one of the most impactful users in the 🤗 Hugging Face community: ranked among the top 100 for Spaces Likes for 12 consecutive months (2024.02–2025.01), for Models Downloads across 11 months, and for Datasets Downloads for 2 months (2024.12–2025.01).
- 2024.09: 🎉🎉 One paper have been accepted by EMNLP 2025! Video-LLaVA!
- 2024.03: 📣📣 We launch a plan to create a simple and scalable repo, Open-Sora Plan, to reproduce Sora!
- 2024.01: 🎉🎉 One paper have been accepted by ICLR 2024! LanguageBind!
- 2023.06: 📣📣 I received my B.E. degree from Sichuan Agricultural University (SICAU), awarded the Outstanding Graduate, ranking 1st/263 in overall scores for three years (2020-2023)!
📝 Selected Publications
*: Co-First Author (Equal Contribution)
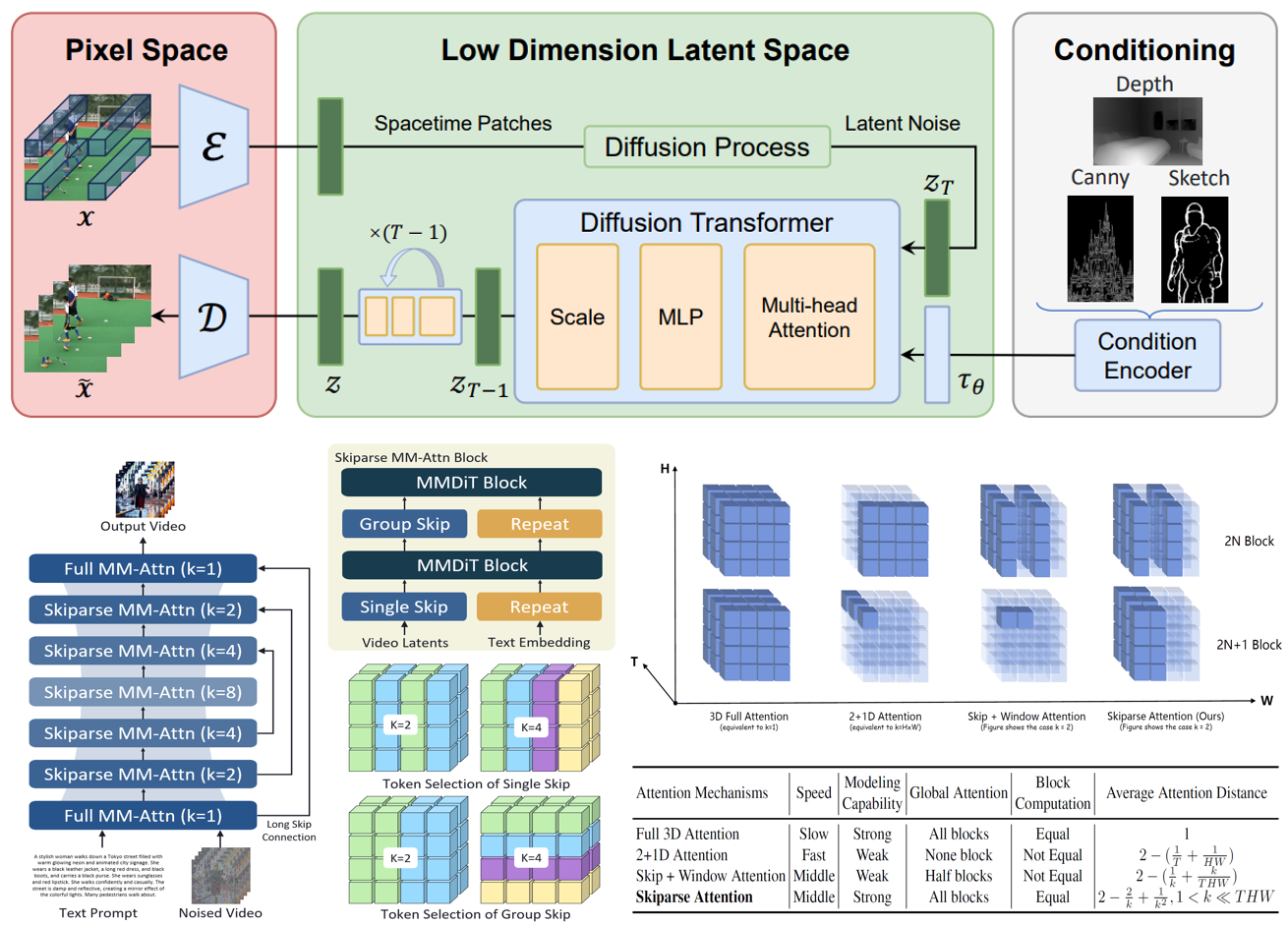
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin*, Yunyang Ge*, Xinhua Cheng*, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, Tanghui Jia, Junwu Zhang, Zhenyu Tang, Yatian Pang, Bin She, Cen Yan, Zhiheng Hu, Xiaoyi Dong, Lin Chen, Zhang Pan, Xing Zhou, Shaoling Dong, Yonghong Tian, Li Yuan.
The first open-source causal VAE for video in v1.0 and v1.1.
The first open-source 3D attention video generation model in v1.2.
The first sparse 3D attention video generation model in v1.3.
The first video generation model natively trained from scratch on NPUs in v1.5.
![]()

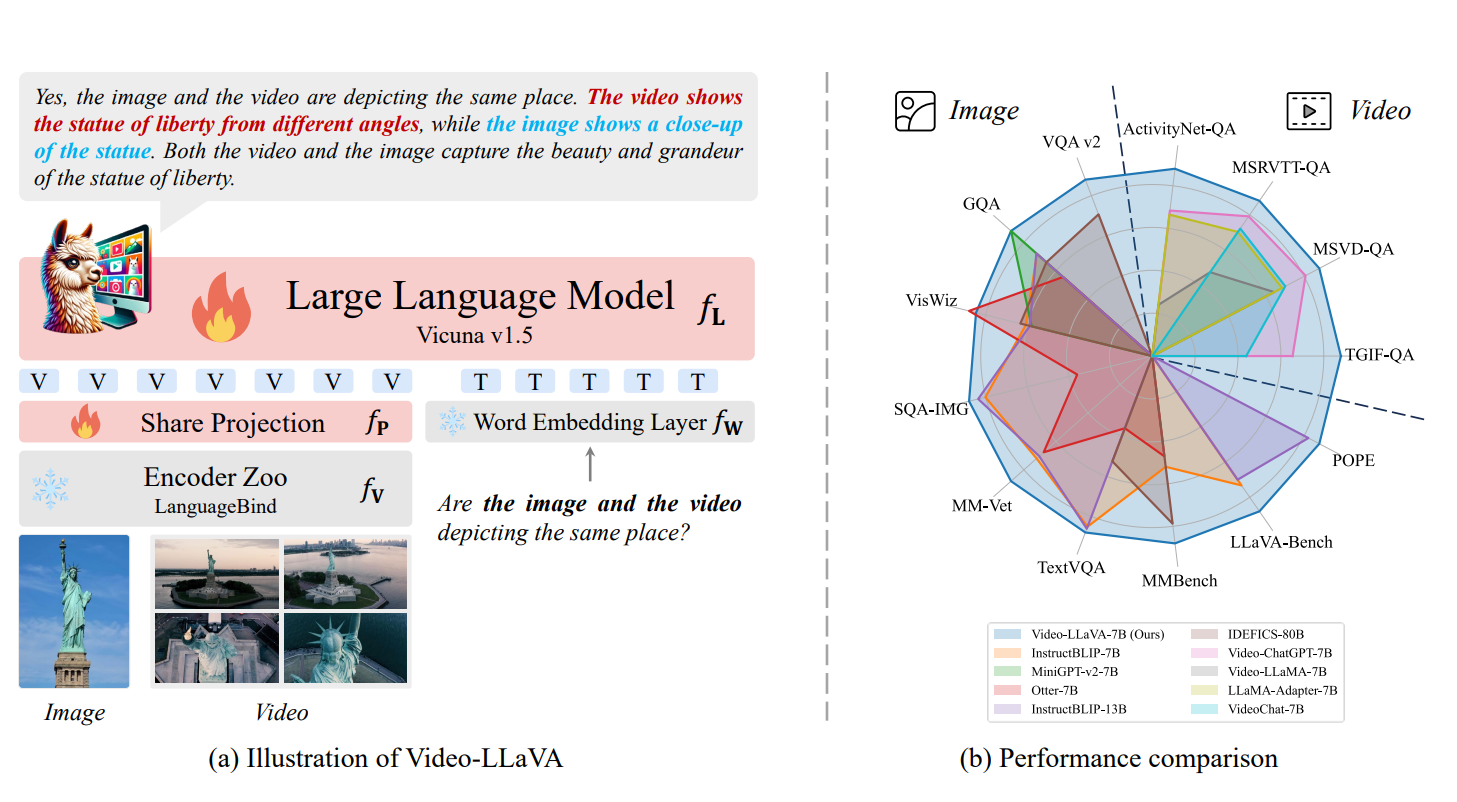
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan
Top 1 of the Most Influential EMNLP 2025 Papers!
Achieved Video-QA SOTA in just 2 days on a single node!
![]()

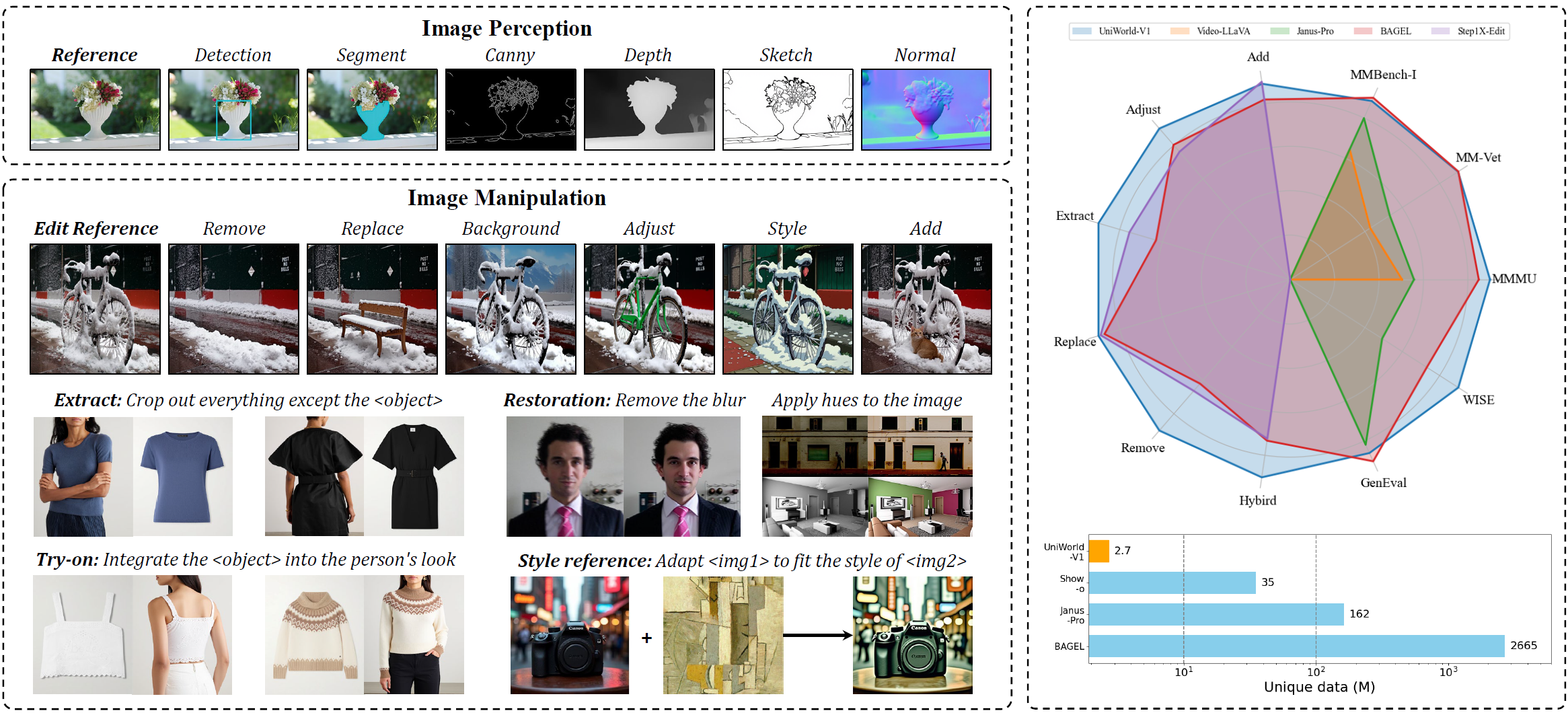
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, Yatian Pang, Li Yuan
2.7M samples enable 20+ tasks, including visual understanding, generation, and manipulation.
![]()

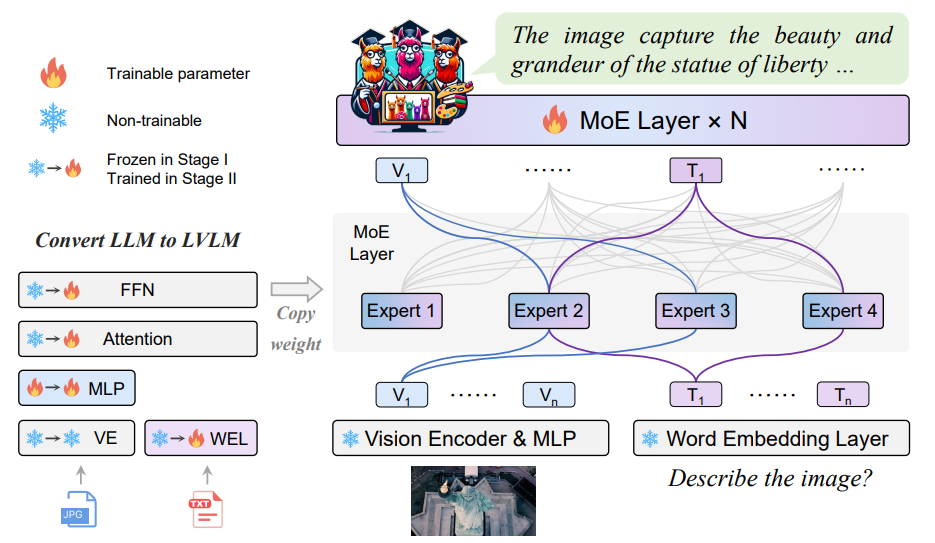
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Bin Lin, Zhenyu Tang, Yang Ye, Jinfa Huang, Junwu Zhang, Yatian Pang, Peng Jin, Munan Ning, Jiebo Luo, Li Yuan
The first Sparse Multi-modal Large Language Model powered by just a single node.
![]()

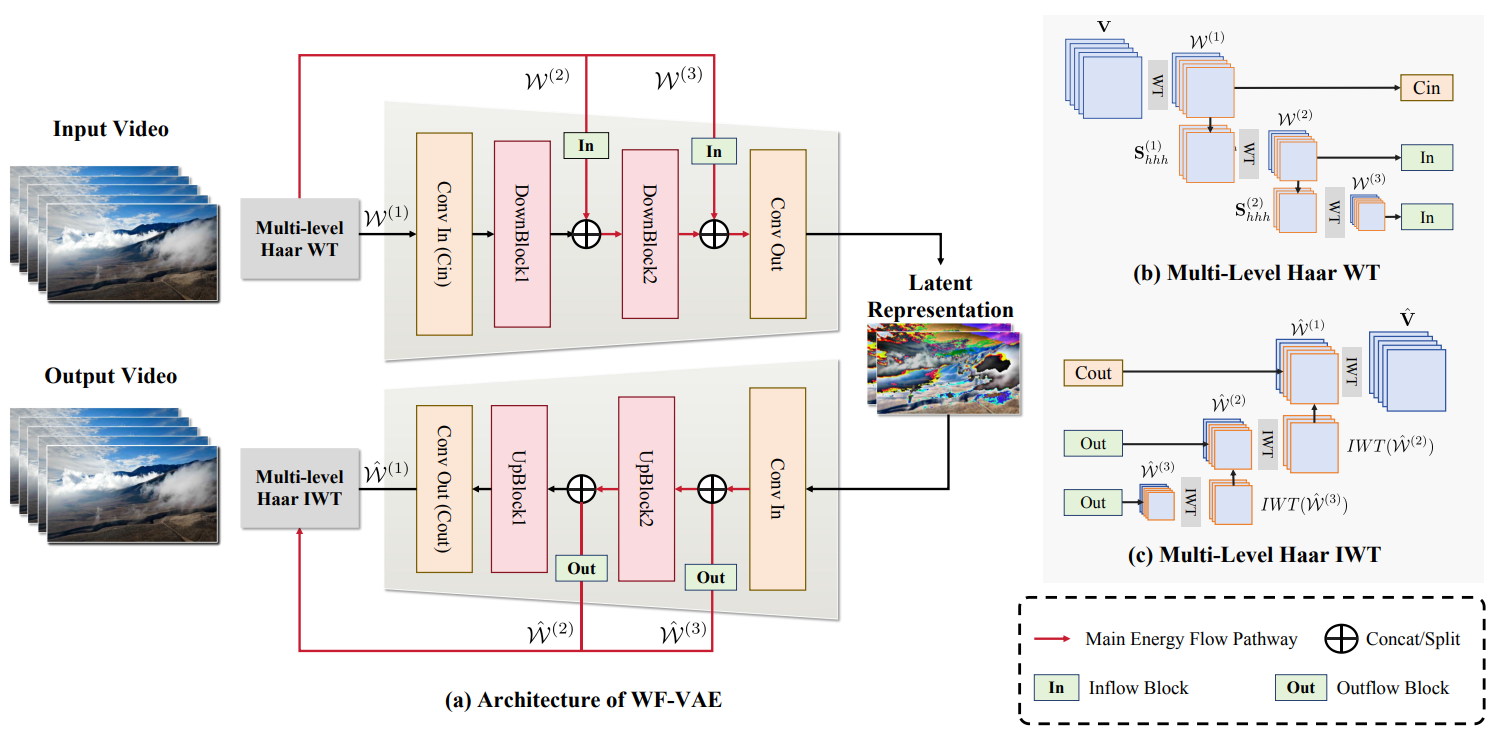
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
Zongjian Li*, Bin Lin*, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, Li Yuan
![]()

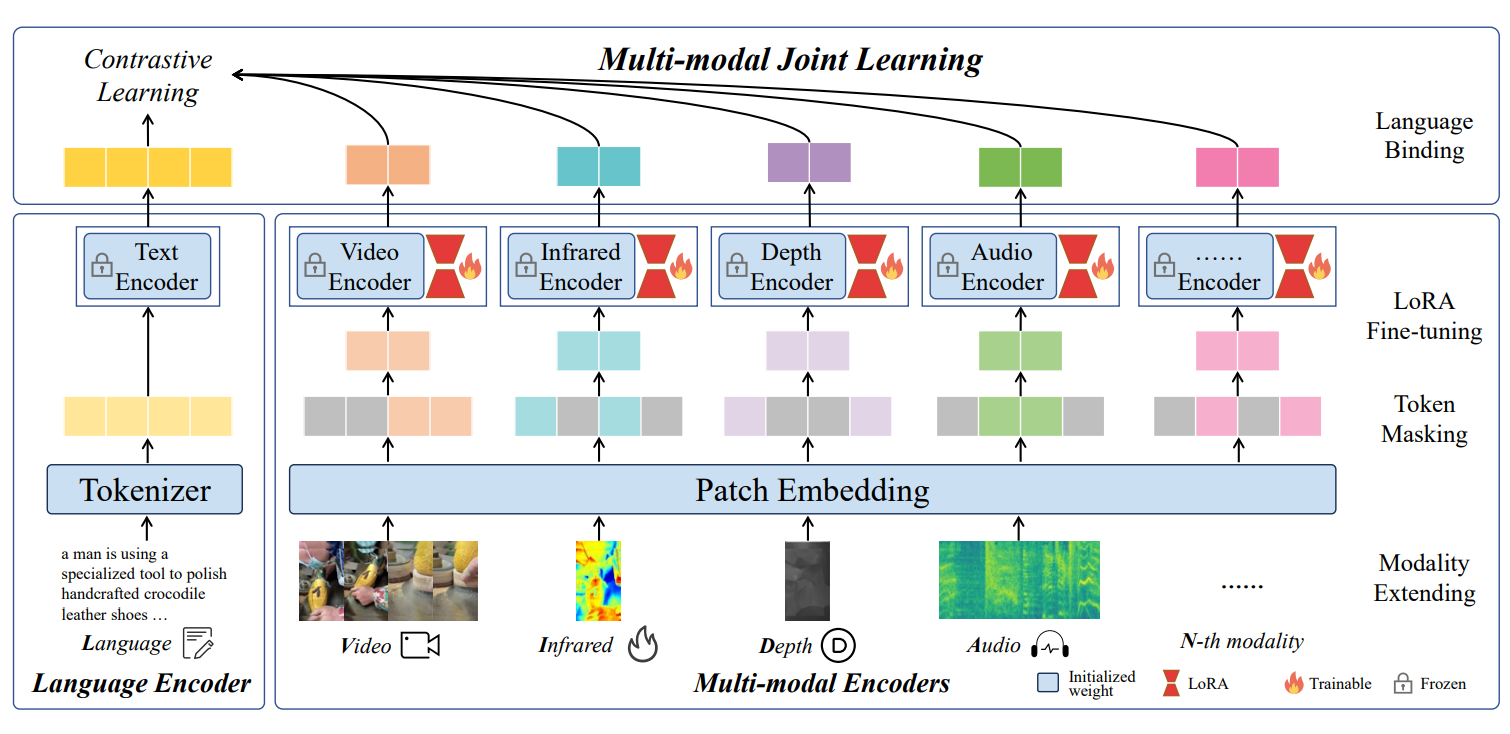
Bin Zhu*, Bin Lin*, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Wancai Zhang, Zhifeng Li, Wei Liu, Li Yuan
![]()

My full paper list is shown at my google scholar.
-
Nature CommunicationsBASALT refines binning from metagenomic data and increases resolution of genome-resolved metagenomic analysis, Zhiguang Qiu, Li Yuan, Chun-Ang Lian, Bin Lin, et al. -
TPAMIMagicTime: Time-lapse Video Generation Models as Metamorphic Simulators, Shenghai Yuan, Jinfa Huang, Yujun Shi, Yongqi Xu, Ruijie Zhu, Bin Lin, et al.
-
ICME 2025OD-VAE: An Omni-dimensional Video Compressor for Improving Latent Video Diffusion Model, Liuhan Chen, Zongjian Li, Bin Lin, et al.
-
NeurIPS 2024ShareGPT4Video: Improving Video Understanding and Generation with Better Captions, Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, et al.
-
NeurIPS 2024 WorkshopTaxDiff: Taxonomic-Guided Diffusion Model for Protein Sequence Generation, Lin Zongying, Li Hao, Lv Liuzhenghao, Bin Lin, et al.
-
PreprintWISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation, Yuwei Niu, Munan Ning, Mengren Zheng, Bin Lin, et al.
-
PreprintImgEdit: A Unified Image Editing Dataset and Benchmark, Yang Ye*, Xianyi He*, Zongjian Li*, Bin Lin*, et al.





🎉 Honors and Awards
- 2023.06 Outstanding graduates from Sichuan Province, China.
- 2022.11 Outstanding Student of Sichuan Agricultural University (10 students).
- 2022.10 National Scholarship (The highest scholarship awarded by the Ministry of Education, China).
- 2021.11 National First Prize of National Undergraduate Mathematical Modeling Contest.
- 2021.10 National Scholarship (The highest scholarship awarded by the Ministry of Education, China).
📖 Educations
- 2023.09 - now (expected: 2028), Ph.D. candidate, Peking University.
- 2019.09 - 2023.06, Undergraduate, Sichuan Agricultural University.