
Bin Lin林彬
Ph.D. Candidate in Computer Science计算机科学博士研究生
Peking University北京大学 · Shenzhen, China中国 · 深圳
linbin.ece@stu.pku.edu.cn · linbin203279@gmail.com
I work on multimodal large models — building open, scalable systems that understand and generate across vision and language, and increasingly unify the two. Advised by Prof. Li Yuan (袁粒) at Peking University.
我的研究方向是多模态大模型——构建开放、可扩展的系统,使其能够跨视觉与语言进行理解与生成,并逐步走向二者的统一。师从北京大学袁粒教授。
I'm a strong believer in open research: I lead and contribute to widely-used projects such as Open-Sora Plan, UniWorld, and Video-LLaVA, releasing the code, models, and data behind every paper.
我笃信开放研究:我主导并参与了多个被广泛使用的项目,如 Open-Sora Plan、UniWorld 和 Video-LLaVA,并为每篇论文开源代码、模型与数据。
News最新动态
- 2026.06Released OSP-Next and GEAR — our latest work on efficient video and autoregressive visual generation.发布 OSP-Next 与 GEAR —— 高效视频生成与自回归视觉生成方向的最新工作。
- 2026.01Selected for the Tencent Project UP Scholarship (腾讯青云奖学金) — one of only 15 awardees nationwide in AI.入选腾讯青云奖学金 —— 全国 AI 领域仅 15 人获此殊荣。
- 2025.07MoE-LLaVA accepted to IEEE Transactions on Multimedia (TMM).MoE-LLaVA 被 IEEE Transactions on Multimedia (TMM) 接收。
- 2025.06Released Open-Sora Plan v1.5 (12K+ ⭐) and launched UniWorld.发布 Open-Sora Plan v1.5(12K+ ⭐),并推出 UniWorld。
- 2025.03Video-LLaVA ranked #1 among the Most Influential EMNLP 2025 Papers.Video-LLaVA 位列 EMNLP 2025 最具影响力论文第 1 名。
- 2025.02WF-VAE accepted to CVPR 2025.WF-VAE 被 CVPR 2025 接收。
- 2024.09Video-LLaVA accepted to EMNLP 2025.Video-LLaVA 被 EMNLP 2025 接收。
- 2024.01LanguageBind accepted to ICLR 2024.LanguageBind 被 ICLR 2024 接收。
Selected Work代表性工作
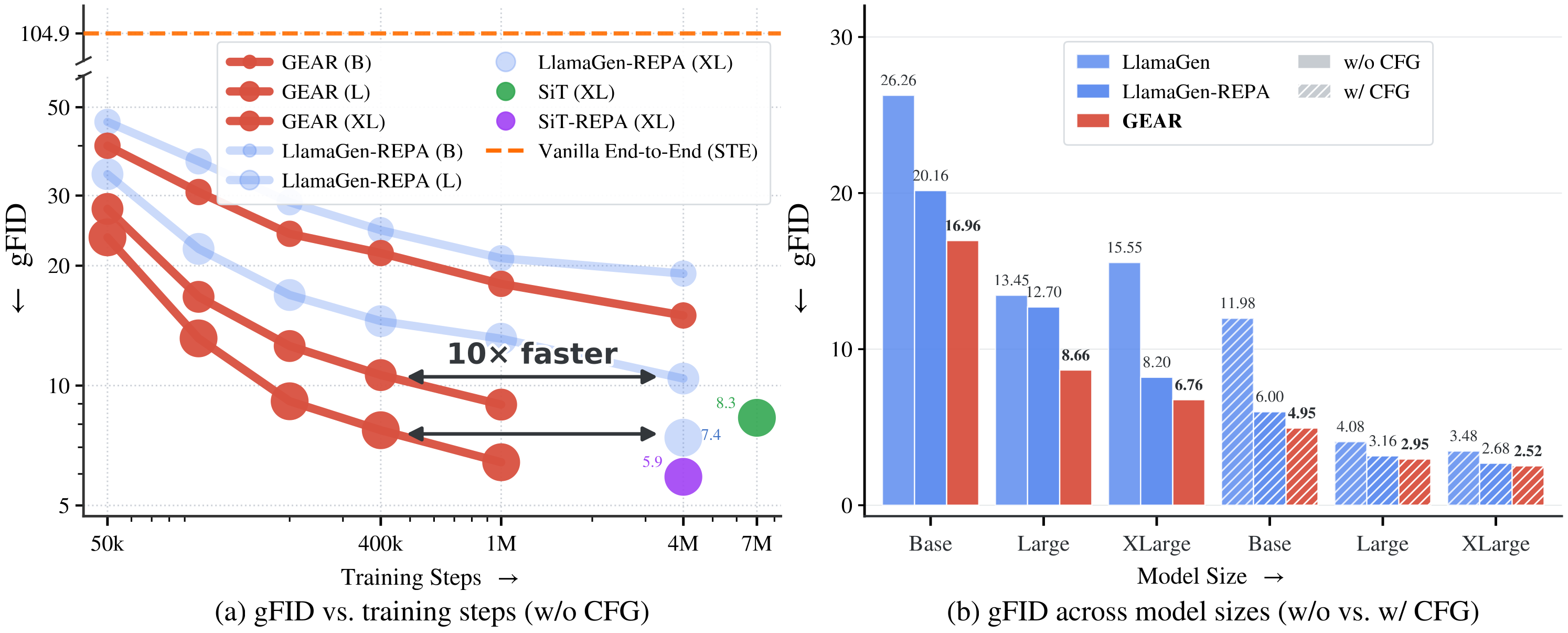
GEAR: Guided End-to-End AutoRegression for Image Synthesis
Jointly trains a VQ tokenizer and an autoregressive generator end-to-end, guided by representation alignment — up to 10× faster AR training than LlamaGen-REPA, with better spatial features that generalize across quantizers and to text-to-image.将 VQ 分词器与自回归生成器端到端联合训练,并由表征对齐引导——自回归训练较 LlamaGen-REPA 最高加速 10×,特征更具空间一致性,且可泛化到多种量化器与文生图。
Open-Sora Plan: Open-Source Large Video Generation Model
A fully open recipe for large-scale video generation — causal video VAE, 3D / sparse attention, and complete training pipelines. The first open model trained from scratch natively on NPUs (v1.5).面向大规模视频生成的全开放方案——因果视频 VAE、3D / 稀疏注意力以及完整的训练流程。首个原生在 NPU 上从零训练的开源模型(v1.5)。
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
One unified model for visual understanding, generation, and manipulation — 2.7M curated samples powering 20+ tasks within a single framework.单一统一模型即可完成视觉理解、生成与编辑——以 270 万条精选数据,在同一框架内支撑 20+ 种任务。
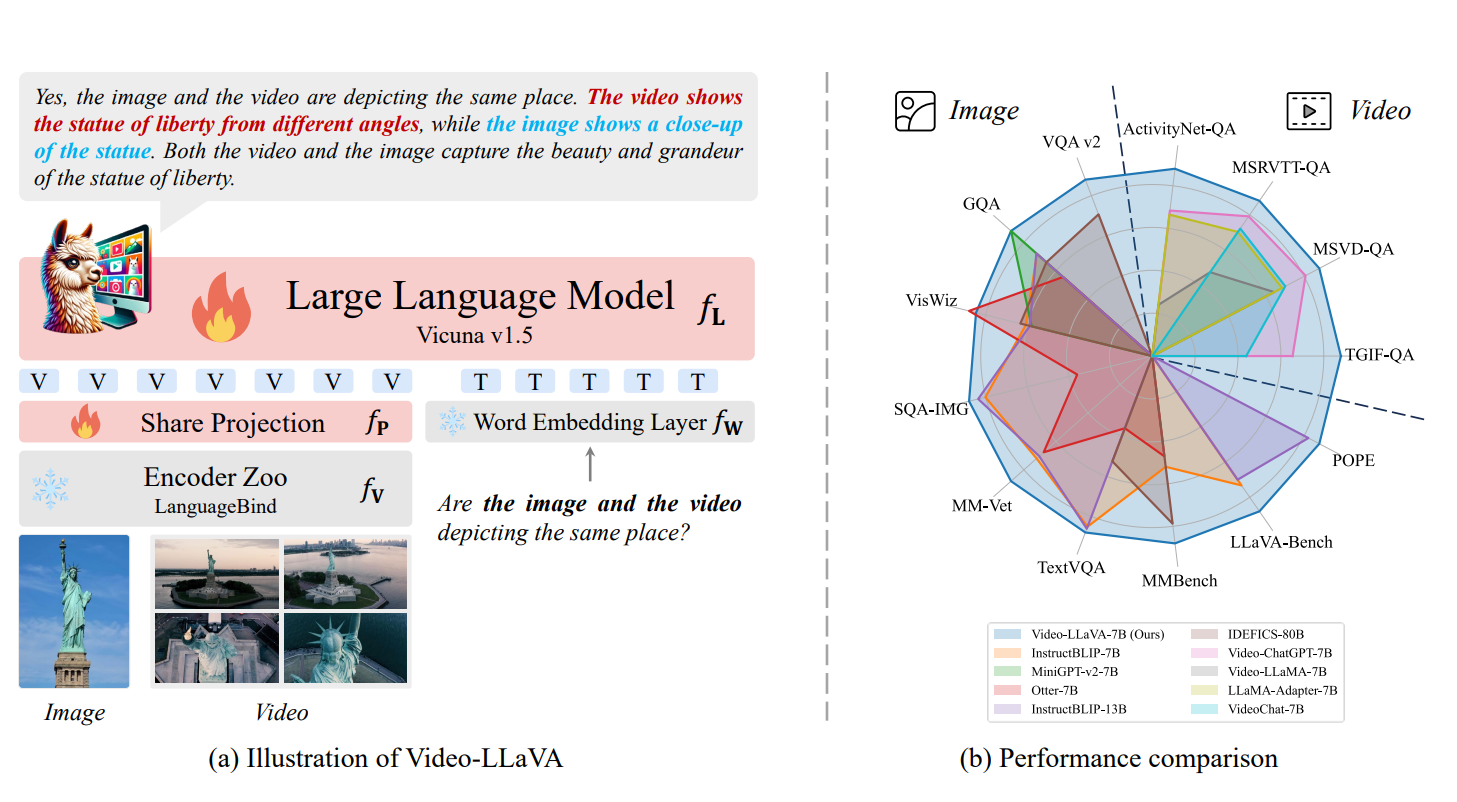
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
#1 Most Influential EMNLP 2025 Paper with 1,000+ citations — reached video-QA SOTA in just two days on a single node.EMNLP 2025 最具影响力论文第 1 名,引用量 1,000+——在单机上仅用两天即达到视频问答 SOTA。
More Publications更多论文
For the complete list, see my Google Scholar. * denotes equal contribution.完整列表见我的 Google Scholar。* 表示共同贡献。
- IEEE TMMFirst Author第一作者 #6 GitHub TrendingGitHub 趋势榜第 6 MoE-LLaVA: Mixture of Experts for Large Vision-Language Models. The first sparse multimodal LLM trainable on a single node.首个可在单机上训练的稀疏多模态大模型。
- CVPR 2025Co-First Author共同一作 WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion. A wavelet-driven video VAE with higher compression efficiency and reconstruction quality.小波驱动的视频 VAE,兼具更高的压缩效率与重建质量。
- ICLR 2024Co-First Author共同一作 LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment. Binds N modalities through language, enabling unified cross-modal pretraining and retrieval.以语言为桥连接 N 种模态,实现统一的跨模态预训练与检索。
- NeurIPS 2025Co-First Author共同一作 ImgEdit: A Unified Image Editing Dataset and Benchmark. A 1.2M-pair image-editing dataset and benchmark, with the ImgEdit-E1 editing model.包含 120 万对样本的图像编辑数据集与基准,并提供 ImgEdit-E1 编辑模型。
- ICML 2026 WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation. A world-knowledge-informed benchmark for evaluating text-to-image generation.引入世界知识的文本到图像生成评测基准。
- NeurIPS 2024 ShareGPT4Video: Improving Video Understanding and Generation with Better Captions. Boosts video understanding and generation with dense, high-quality captions.借助密集且高质量的视频描述,提升视频理解与生成能力。
Open-Source Projects开源项目
Open source is at the core of my research — collectively 20K+ GitHub stars and 14M+ model & data downloads.开源是我研究的核心 —— 累计获得 20K+ GitHub Stars,相关模型与数据下载量超过 14M+。
Honors & Awards荣誉与奖项
- 2023.06Outstanding Graduate of Sichuan Province, China.四川省优秀毕业生。
- 2022.11Outstanding Student, Sichuan Agricultural University (top 10 university-wide).四川农业大学优秀学生(全校前 10)。
- 2022.10National Scholarship — highest scholarship from the Ministry of Education, China.国家奖学金 —— 教育部最高奖学金。
- 2021.11National First Prize, National Undergraduate Mathematical Modeling Contest.全国一等奖,全国大学生数学建模竞赛。
- 2021.10National Scholarship — highest scholarship from the Ministry of Education, China.国家奖学金 —— 教育部最高奖学金。
Education教育经历
Peking University北京大学
Sichuan Agricultural University四川农业大学